
# 基础概念
uniCloud提供了一个 JSON 格式的文档型数据库。顾名思义,数据库中的每条记录都是一个 JSON 格式的文档。
它是nosql非关系型数据库,如果您之前熟悉sql关系型数据库,那么两者概念对应关系如下表:
| 关系型 | JSON 文档型 |
|---|---|
| 数据库 database | 数据库 database |
| 表 table | 集合 collection。但行业里也经常称之为“表”。无需特意区分 |
| 行 row | 记录 record / doc |
| 字段 column | 字段 field |
| 使用sql语法操作 | 使用MongoDB语法或jql操作 |
一个uniCloud服务空间,有且只有一个数据库。一个数据库支持多个集合(表)。一个集合可以有多个记录。每个记录可以有多个字段。
例如,数据库中有一个集合,名为user,存放用户信息。集合user的数据内容如下:
{"name":"张三","tel":"13900000000"}
{"name":"李四","tel":"13911111111"}
上述数据中,每行数据表示一个用户的信息,被称之为“记录(record/doc)”。name和tel称之为“字段(field)”。而“13900000000”则是第一条记录的字段tel的值。
每行记录,都是一个完整的json文档,获取到记录后可以使用常规json方式操作。但集合并非json文档,集合是多个json文档的汇总,获取集合需要使用专门的API。
与关系型数据库的二维表格式不同,json文档数据库支持不同记录拥有不同的字段、支持多层嵌套数据。
仍然以user集合举例,要在数据库中存储每个人的每次登录时间和登录ip,则变成如下:
{
"name":"张三","tel":"13900000000",
"login_log":[
{"login_date":1604186605445,"login_ip":"192.168.1.1"},
{"login_date":1604186694137,"login_ip":"192.168.1.2"}
]
}
{"name":"李四","tel":"13911111111"}
上述数据表示张三登录了2次,login_date里的值是时间戳(timestamp)格式,在数据库内timestamp就是一个数字类型的数据。而李四没有登录过。
可以看出json文档数据库相对于关系型数据库的灵活,李四可以没有login_log字段,也可以有这个字段但登录次数记录与张三不同。
此处仅为举例,实际业务中,登录日志单独存放在另一个集合更好
对于初学者,如果不了解数据库设计,可以参考opendb (opens new window),已经预置了大量常见的数据库设计。
对于不熟悉传统数据库,但掌握json的js工程师而言,uniCloud的云数据库更亲切,没有传统数据库高昂的学习成本。
在uniCloud web控制台新建表时,在下面的模板中也可以选择各种opendb表模板,直接创建。
uniCloud同时支持阿里云和腾讯云,它们的数据库大体相同,有细微差异。阿里云的数据库是mongoDB4.0,腾讯云则使用自研的文档型数据库(兼容mongoDB 4.0版本)。uniCloud基本抹平了不同云厂商的差异,有差异的部分会在文档中单独标注。
如果想在云函数连接其他数据库,如mysql,用法和nodejs连接这些数据库是一样的。插件市场已经有人提供了插件,见下。但注意这些用法推荐用于数据导入,主业务开发不建议这么使用。因为其他服务器上的数据库和云函数环境物理上不在一起,连接会比较慢。
如需使用redis,请参考文档:Redis扩展库
# 操作数据库的方式
云数据库支持通过云函数访问,也支持在客户端访问云数据库。
- 传统方式云函数操作数据库,使用nodejs写云函数、使用传统的MongoDB的API操作云数据库。
- 客户端访问云数据库,称为clientDB。这种开发方式可大幅提升开发效率,避免开发者开发服务器代码,并且支持更易用的
jql语法操作数据库,是更为推荐的开发方式。clientDB有单独一套权限和字段值控制系统,无需担心数据库安全。需要HBuilderX 2.9.5及以上版本 - 云函数内使用jql语法操作数据库,需要使用jql扩展库。与clientDB写法一致,仅在访问password类型的数据时有区别。clientDB完全不可访问password类型字段(即使为此字段设置permission也不生效)。云函数内password类型字段默认权限为false(可以被admin用户访问),开发者配置的字段权限会覆盖此默认权限。需要
HBuilderX 3.3.1及以上版本
不管使用哪种方法,都有很多公共的概念或功能。本文档将讲述这些公共的内容。
同时左侧导航有三种方法的专项链接,描述它们各自特有的功能。
# 获取数据库对象
想要通过代码操作数据库,第一步要获取服务空间里的数据库对象。
云函数使用传统MongoDB语法操作数据库以及客户端使用clientDB获取数据库实例:
const db = uniCloud.database(); //代码块为cdb
js中敲下代码块cdb,即可快速输入上述代码。
云函数内使用JQL扩展库时获取数据库实例写法为:
// 简单的使用示例
'use strict';
exports.main = async (event, context) => {
const dbJQL = uniCloud.databaseForJQL({ // 获取JQL database引用,此处需要传入云函数的event和context,必传
event,
context
})
const bookQueryRes = dbJQL.collection('book').where("name=='三国演义'").get() // 直接执行数据库操作
return {
bookQueryRes
}
};
# 获取其他服务空间数据库实例
如果当前应用仅使用一个服务空间,在HBuilderX中做好服务空间关联即可。获取当前空间的数据库实例时无需传递配置,直接调用database方法即可
const db = uniCloud.database()
如果应用有连接其他服务空间数据库的需求,可以在获取database实例时传递对应服务空间的配置
HBuilderX 3.2.11及更高版本支持客户端初始化其他服务空间database实例,此前仅腾讯云云函数环境支持。阿里云云函数环境不支持此用法。
调用uniCloud.database()时可以传入对应的服务空间信息(参数同uniCloud.init,参考:uniCloud.init)来获取指定服务空间的database实例。
注意
- 云函数环境(仅腾讯云支持)仅能通过init返回同账号下其他的腾讯云服务空间的数据库实例。
- 客户端环境(腾讯云阿里云均支持)可以通过init返回本账号下任意云厂商服务空间的数据库实例
示例
const db = uniCloud.database({
provider: 'tencent',
spaceId: 'xxx'
})
db.collection('uni-id-users').get()
参数说明
| 参数名 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
| provider | String | 是 | - | aliyun、tencent |
| spaceId | String | 是 | - | 服务空间ID,注意是服务空间ID,不是服务空间名称 |
| clientSecret | String | 是 | - | 仅阿里云支持,可以在uniCloud控制台 (opens new window)服务空间列表中查看 |
| endpoint | String | 否 | https://api.bspapp.com | 服务空间地址,仅阿里云侧支持 |
# 创建一个集合/数据表
新建的服务空间,没有数据表。需要首先创建集合/数据表。
可以在uniCloud的web控制台(https://unicloud.dcloud.net.cn (opens new window))在web页面创建数据表,也可以通过代码创建数据表。
通过代码创建数据表的方式,阿里云和腾讯云有差别:
- 阿里云
调用add方法,给某数据表新增数据记录时,如果该数据表不存在,会自动创建该数据表。如下代码给table1数据表新增了一条数据,如果table1不存在,会自动创建。
const db = uniCloud.database();
db.collection("table1").add({name: 'Ben'})
- 腾讯云
腾讯云提供了专门的创建数据表的API,此API仅支持云函数内运行,不支持clientDB调用。
const db = uniCloud.database();
db.createCollection("table1")
注意
- 如果数据表已存在,腾讯云调用createCollection方法会报错
- 腾讯云调用collection的add方法不会自动创建数据表,不存在的数据表会报错
- 阿里云没有createCollection方法
- 使用代码方式创建的表没有索引,请谨慎使用此方式
# 获取集合/数据表对象
创建好数据表后,可以通过API获取数据表对象。
const db = uniCloud.database();
// 获取名为 `table1` 数据表的引用
const collection = db.collection('table1');
集合/数据表 Collection 的方法
通过 db.collection(name) 可以获取指定数据表的引用,在数据表上可以进行以下操作
| 类型 | 接口 | 说明 |
|---|---|---|
| 写 | add | 新增记录(触发请求) |
| 计数 | count | 获取符合条件的记录条数 |
| 读 | get | 获取数据表中的记录,如果有使用 where 语句定义查询条件,则会返回匹配结果集 (触发请求) |
| 引用 | doc | 获取对该数据表中指定 id 的记录的引用 |
| 查询条件 | where | 通过指定条件筛选出匹配的记录,可搭配查询指令(eq, gt, in, ...)使用 |
| skip | 跳过指定数量的文档,常用于分页,传入 offset。clientDB组件有封装好的更易用的分页,另见 | |
| orderBy | 排序方式 | |
| limit | 返回的结果集(文档数量)的限制,有默认值和上限值 | |
| field | 指定需要返回的字段 |
collection对象的方法可以增和查数据,删和改不能直接操作,需要collection对象通过doc或get得到指定的记录后再调用remove或update方法进行删改。
具体前端clientDB和云函数各自增删改查的方法,请单独参考文档:
# 数据类型
数据库内数据基础类型有以下几种:
- String:字符串
- Number:数字
- Object:对象
- Array:数组
- Bool:布尔值
- GeoPoint:地理位置点
- GeoLineStringLine: 地理路径
- GeoPolygon: 地理多边形
- GeoMultiPoint: 多个地理位置点
- GeoMultiLineString: 多个地理路径
- GeoMultiPolygon: 多个地理多边形
- Date:时间
- Null:相当于一个占位符,表示一个字段存在但是值为空。
DB Schema中还扩展了其他字段类型,但其实都是基本类型的扩展,比如file类型其实是一种特殊的object,而password类型是一种特殊的string类型。
# Date类型
Date 类型用于表示时间,精确到毫秒,可以用 JavaScript 内置 Date 对象创建。需要特别注意的是,连接本地云函数时,用此方法创建的时间是客户端当前时间,不是服务端当前时间,只有连接云端云函数才是服务端当前时间。
另外,我们还单独提供了一个 API 来创建服务端当前时间,使用 serverDate 对象来创建一个服务端当前时间的标记,该对象暂时只支持腾讯云空间,当使用了 serverDate 对象的请求抵达服务端处理时,该字段会被转换成服务端当前的时间,更棒的是,我们在构造 serverDate 对象时还可通过传入一个有 offset 字段的对象来标记一个与当前服务端时间偏移 offset 毫秒的时间,这样我们就可以达到比如如下效果:指定一个字段为服务端时间往后一个小时。
// 服务端当前时间
new db.serverDate()
// 在云函数内使用new Date()和new db.serverDate()效果一样
//服务端当前时间加1S
new db.serverDate({
offset: 1000
})
// 在云函数内使用new Date(Date.now() + 1000)和上面的用法效果一样
# 地理位置类型
# Point
用于表示地理位置点,用经纬度唯一标记一个点,这是一个特殊的数据存储类型。
签名:Point(longitude: number, latitude: number)
示例:
new db.Geo.Point(longitude, latitude)
# LineString
用于表示地理路径,是由两个或者更多的 Point 组成的线段。
签名:LineString(points: Point[])
示例:
new db.Geo.LineString([
new db.Geo.Point(lngA, latA),
new db.Geo.Point(lngB, latB),
// ...
])
# Polygon
用于表示地理上的一个多边形(有洞或无洞均可),它是由一个或多个闭环 LineString 组成的几何图形。
由一个环组成的 Polygon 是没有洞的多边形,由多个环组成的是有洞的多边形。对由多个环(LineString)组成的多边形(Polygon),第一个环是外环,所有其他环是内环(洞)。
签名:Polygon(lines: LineString[])
示例:
new db.Geo.Polygon([
new db.Geo.LineString(...),
new db.Geo.LineString(...),
// ...
])
# MultiPoint
用于表示多个点 Point 的集合。
签名:MultiPoint(points: Point[])
示例:
new db.Geo.MultiPoint([
new db.Geo.Point(lngA, latA),
new db.Geo.Point(lngB, latB),
// ...
])
# MultiLineString
用于表示多个地理路径 LineString 的集合。
签名:MultiLineString(lines: LineString[])
示例:
new db.Geo.MultiLineString([
new db.Geo.LineString(...),
new db.Geo.LineString(...),
// ...
])
# MultiPolygon
用于表示多个地理多边形 Polygon 的集合。
签名:MultiPolygon(polygons: Polygon[])
示例:
new db.Geo.MultiPolygon([
new db.Geo.Polygon(...),
new db.Geo.Polygon(...),
// ...
])
# 集合/数据表的3个组成部分
每个数据表,其实包含3个部分:
- data:数据内容
- index:索引
- schema:数据表格式定义
在uniCloud的web控制台可以看到一个数据表的3部分内容。
# 数据内容
data很简单,就是存放的数据记录(record)。
实际上,创建一条新记录,是不管在web控制台创建,还是通过API创建,每条记录都会自带一个_id字段用以作为该记录的唯一标志。
_id字段是每个数据表默认自带且不可删除的字段。同时,它也是数据表的索引。
阿里云使用的是标准的mongoDB,_id是自增的,后创建的记录的_id总是大于先生成的_id。传统数据库的自然数自增字段在多物理机的大型数据库下很难保持同步,大型数据库均使用_id这种长度较长、不会重复且仍然保持自增规律的方式。
腾讯云使用的是兼容mongoDB的自研数据库,_id并非自增
插入/导入数据时也可以自行指定_id而不使用自动生成的_id,这样可以很方便的将其他数据库的数据迁移到uniCloud云数据库
# 数据库索引
所谓索引,是指在数据表的众多字段中挑选一个或多个字段,让数据库引擎优先处理这些字段。设置为索引的字段,在通过该字段查询记录时可以获得更快的查询速度。但设置过多索引也不合适,会造成数据新增和删除变慢。
一个数据表可以有多个字段被设为索引。
索引分唯一型和非唯一型。
唯一型索引要求整个数据表多个记录的该字段的值不能重复。比如_id就是唯一型索引。
假使有2个人都叫“张三”,那么他们在user数据表里的区分就是依靠不同的_id来区分。
如果我们要根据name字段来查询,为了提升查询速度,此时可以把name字段设为非唯一索引。
索引内容较多,还有“组合索引”、“稀疏索引”、“地理位置索引”、“TTL索引”等概念。有单独的文档详细讲述索引,另见:数据库索引
在web控制台添加上述索引

注意
- 如果记录中已经存在多个记录某字段相同的情况,那么将该字段设为唯一型索引会失败。
- 如果已经设置某字段为唯一索引,在新增和修改记录时如果该字段的值之前在其他记录已存在,会失败。
- 假如记录中不存在某个字段,则对索引字段来说其值默认为 null,如果该索引字段设为唯一型索引,则不允许存在两个或以上的该字段为null或不存在该字段的记录。此时需要设置稀疏索引来解决多个null重复的问题
# 数据表格式定义
DB Schema是集合的表结构描述。描述数据表有哪些字段、值域类型是什么、是否必填、数据操作权限等很多内容。
因为json文档数据库的灵活性,data数据的字段可以不在schema的描述范围内。
DB Schema更多是为搭配jql语法使用的,如果使用jql语法(clientDB或者使用了jql扩展库的云函数内)则需要详细阅读DB Schema的文档。
DB Schema涉及内容较多,另见文档:/uniCloud/schema
# 与传统开发区别
不同于传统开发,云函数连接数据库有单次操作时长限制,目前单次操作时间限制如下。超出此时间会报超时错误。一般情况下在设置了合适的索引时不会遇到超时错误,如何优化查询速度请参考:数据库性能优化
| 腾讯云 | 阿里云 |
|---|---|
| 5秒 | 1秒 |
# 数据导入导出和备份
uniCloud数据库提供了多种数据导入导出和备份方案。
- db_init.json:常用于插件市场的插件做环境初始化。完整支持数据、索引、schema三部分。不适合处理大量数据,操作可能超时
- 数据库回档备份和恢复。仅腾讯云支持。支持数据和索引,不支持schema
- 数据库导入导出。仅阿里云支持,适用于大数据量操作。仅支持数据,不支持索引和schema
除上述三种方法外,开发者还可以编程处理数据的导入导出。如进行大量数据操作,建议在HBuilderX的本地运行云函数环境中操作,这样可以避免触发云端的云函数超时限制。
下面对三种方法的使用方式进行详细说明:
# db_init.json初始化数据库
db_init.json定义了一个json格式,里面包含了表名、表数据、表索引等表的相关数据。
在HBuilderX中,项目的cloudfunctions目录(HBuilderX 2.5.11 - 2.9.11版本) 或 uniCloud/database 目录(HBuilderX 3.0+版本),可以放置db_init.json文件,对该文件点右键,可以按db_init.json的描述,在云服务空间创建相应的表、初始化表中的数据、索引和schema。
这个功能尤其适合插件作者,可以快速初始化插件所需的数据库环境。
db_init.json的数据格式
db_init.json包含三部分:数据内容(data)、数据表索引(index)、数据表结构(schema),形式如下
注意:HBuilderX 3.0.0以上版本schema不再放在db_init.json内,而是独立放在uniCloud/database/目录下。
详细调整如下:
- db_init.json位置由
cloudfunctions/db_init.json移至uniCloud/database/db_init.json - schema不再放在db_init.json内,每个表都有一个单独的schema文件,比如news表对应的schema为
uniCloud/database/news.schema.json - schema可以在
uniCloud/database目录上右键创建 db_init.json文件右键初始化云数据库时依然会带上schema进行数据库的初始化,除schema外HBuilderX3.0.0以上版本使用db_init.json初始化数据库还会带上扩展校验函数,扩展校验函数位于uniCloud/database/validateFunction目录下,扩展校验函数文档详见:validateFunction
HBuilderX 3.0.0版本之前的db_init.json示例
{
"collection_test": { // 集合(表名)
"data": [ // 数据
{
"_id": "da51bd8c5e37ac14099ea43a2505a1a5", // 一般不带_id字段,防止导入时数据冲突。
"name": "tom"
}
],
"index": [{ // 索引
"IndexName": "index_a", // 索引名称
"MgoKeySchema": { // 索引规则
"MgoIndexKeys": [{
"Name": "index", // 索引字段
"Direction": "1" // 索引方向,1:ASC-升序,-1:DESC-降序,2dsphere:地理位置
}],
"MgoIsUnique": false, // 索引是否唯一
"MgoIsSparse": false // 是否为稀疏索引,请参考 /uniCloud/db-index.md?id=sparse
}
}],
"schema": { // HBuilderX 3.0.0以上版本schema不在此处,而是放在database目录下单独的`表名.schema.json`文件内
"bsonType": "object",
"permission": {
".read": true,
".create": false,
".update": false,
".delete": false
},
"required": [
"image_url"
],
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"image_url": {
"bsonType": "string",
"description": "可以是在线地址,也支持本地地址",
"label": "图片url"
}
}
}
}
}
在HBuilderX中对上述db_init.json点右键,可初始化数据库到云服务空间,创建collection_test表,并按上述json配置设置该表的index索引和schema,以及插入data下的数据。
opendb (opens new window)的表,在db_init.json中初始化时,不建议自定义index和schema。系统会自动从opendb规范中读取最新的index和schema。
使用db_init.json导入数据库
在HBuilderX中,对项目下的cloudfunctions目录下的db_init.json点右键,即可选择初始化云数据库。将db_init.json里的内容导入云端。
注意事项:
- 目前
db_init.json为同步导入形式,无法导入大量数据。导入大量数据请使用web控制台的数据库的导入功能。 - 如果
db_init.json中的表名与opendb中任意表名相同,且db_init.json中该表名内没有编写schema和index,则在初始化时会自动拉取最新的opendb规范内对应表的schema和index。 - 如果
db_init.json中的数据表在服务空间已存在,且db_init.json中该表含有schema和index,则在初始化时schema会被替换,新增索引会被添加,已存在索引不受影响。
生成db_init.json的方式
在uniCloud web控制台的数据库界面,左侧导航点击 生成db_init.json,会将选择的表的内容、索引、表结构导出为db_init.json文件。
注意事项:
- 如果表名与opendb中任意表名相同,web控制台导出时将不会带上schema和index。
- web控制台导出时默认不包括
_id字段,在导入时,数据库插入新记录时会自动补_id字段。如果需要指定_id,需要手工补足数据。
在db_init.json内可以使用以下形式定义Date类型的数据:
{
"dateObj": { // dateObj字段就是日期类型的数据
"$date": "2020-12-12T00:00:00.000Z" // ISO标准日期字符串
}
}
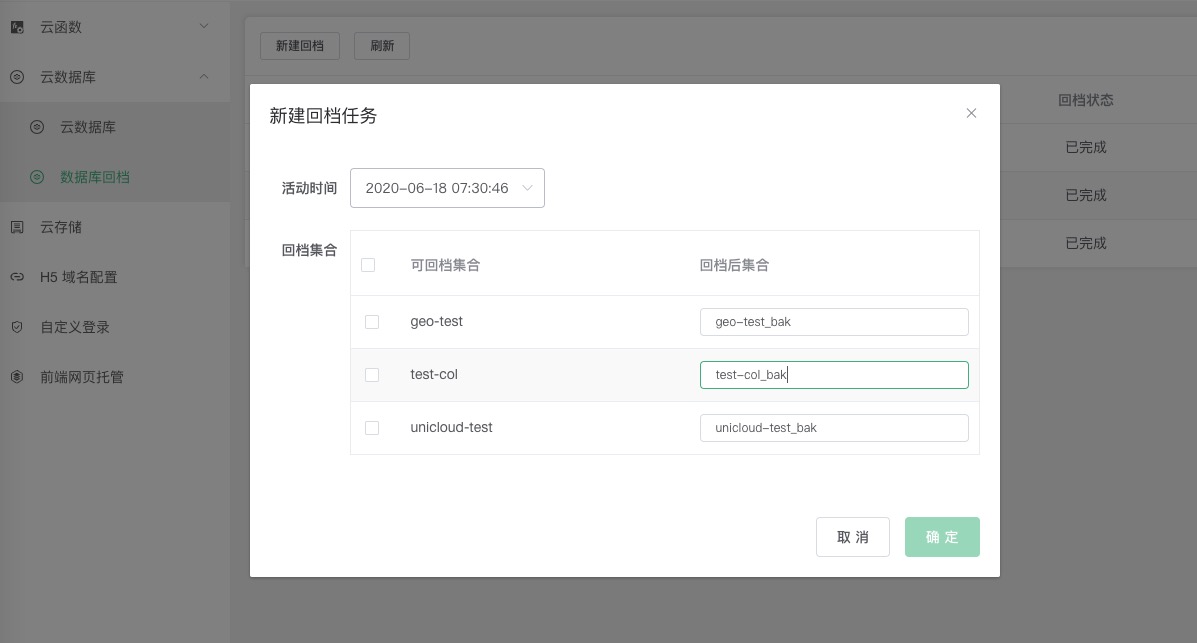
# 数据库回档备份和恢复
uniCloud会在每天凌晨自动备份一次数据库,最多保留7天。这让开发者不再担心数据丢失。
操作说明
- 登录uniCloud后台 (opens new window)
- 点击左侧菜单
云数据库 --> 数据库回档,点击新建回档 - 选择可回档时间
- 选择需要回档的集合(注意:回档后集合不能与现有集合重名,如需对集合重命名可以在集合列表处操作)
# 数据导出为文件
此功能主要用于导出整个集合的数据
用法
- 进入uniCloud web控制台 (opens new window),选择服务空间,或者直接在HBuilderX云函数目录
cloudfunctions上右键打开uniCloud web控制台 - 进入云数据库选择希望导入数据的集合
- 点击导出按钮
- 选择导出格式,如果选择csv格式还需要选择导出字段
- 点击确定按钮等待下载开始即可
注意
- 导出的json文件并非一般情况下的json,而是每行一条json数据的文本文件
- 导出为csv格式时必须填写字段选项。字段之间使用英文逗号隔开。例如:
_id, name, age, gender - 导出为csv格式会丢失数据类型,如需迁移数据库请导出为json格式
- 数据量较大时可能需要等待一段时间才可以开始下载
# 从文件导入数据
uniCloud提供的db_init.json主要是为了对数据库进行初始化,并不适合导入大量数据。与db_init.json不同,数据导入功能可以导入大量数据,目前支持导入 CSV、JSON 格式(关于json格式看下面注意事项)的文件数据。
用法
- 进入uniCloud web控制台 (opens new window),选择服务空间,或者直接在HBuilderX云函数目录
cloudfunctions上右键打开uniCloud web控制台 - 进入云数据库选择希望导入数据的集合
- 点击导入,选择json文件或csv文件
- 选择处理冲突模式(关于处理冲突模式请看下方注意事项)
- 点击确定按钮等待导入完成即可
注意
- 目前导入文件最大限制为50MB
- 导入导出文件无法保留索引和schema
- 导入导出csv时数据类型会丢失,即所有字段均会作为字符串导入
- 冲突处理模式为设定记录_id冲突时的处理方式,
insert表示冲突时依旧导入记录但是是新插入一条,upsert表示冲突时更新已存在的记录 - 这里说的json文件并不是标准的json格式,而是形如下面这样每行一个json格式的数据库记录的文件
{"a":1} {"a":2}
如果是自己拼接的json格式数据请注意:如果存在集合A关联集合B的字段的场景需要保证关联字段在A、B内是一致的(特别需要注意的是各种与_id关联的字段)
例:
正确示例
// 这里为了方便看数据进行了格式化,实际导入所需的json文件是每行一条记录
// article集合
{
"user_id": {
$oid: "601cf1dbf194b200018ed8ec"
}
}
// user集合
{
"_id": {
$oid: "601cf1dbf194b200018ed8ec"
}
}
错误示例
// 这里为了方便看数据进行了格式化,实际导入所需的json文件是每行一条记录
// article集合
{
"user_id": "601cf1dbf194b200018ed8ec"
}
// user集合
{
"_id": {
$oid: "601cf1dbf194b200018ed8ec"
}
}
# 云厂商之间的迁移
文档移至:在云厂商之间迁移数据库